
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- MYSQL
- SQL
- 데이터분석
- 데이터리안
- python
- regexp
- 신입 데이터분석가
- 순위함수
- 누적합
- advent of sql
- SolveSQL
- Datarian
- pandas
- 프로그래머스
- dense_rank
- 서브쿼리
- leetcode
- Retention
- 린분석
- row_number
- 윈도우 함수
- rank
- 취준
- funnel
- 퍼널분석
- 리텐션
- 그로스해킹
- LEFTJOIN
- 윈도우함수
- 독서
- Today
- Total
데이터 분석
대장균의 크기에 따라 분류하기 2 | Lv.3 | PERCENT_RANK()💡 본문
문제
대장균 개체의 크기를 내림차순으로 정렬했을 때 상위 0% ~ 25% 를 'CRITICAL', 26% ~ 50% 를 'HIGH', 51% ~ 75% 를 'MEDIUM', 76% ~ 100% 를 'LOW'라고 분류합니다. 대장균 개체의 ID(ID)와 분류된 이름(COLONY_NAME)을 출력하는 SQL 문을 작성해 주세요. 이때 결과는 개체의 ID에 대해 오름차순 정렬해 주세요. 단, 총 데이터의 수는 4의 배수이며 같은 사이즈의 대장균 개체가 서로 다른 이름으로 분류되는 경우는 없습니다.
📌 내 생각
'같은 사이즈의 대장균 개체는 반드시 같은 이름으로 분류된다'는 조건이 있기 때문에, DENSE_RANK 함수는 정답으로 처리되지 않는다. 추가로 더 엄밀하게 생각해 보면, ROW_NUMBER 함수 또한 위 문제의 조건에 위배되는 경우가 존재하여 정답이 되서는 안 된다고 생각한다.
총 데이터 수는 4의 배수라는 가정이 있기 때문에, 총 12개의 아래와 같은 데이터가 있다고 하자.
| SIZE_OF_COLONY | ROW_NUMBER | RANK | ROW_NUMBER에 의한 분류 | RANK에 의한 분류 |
| 101 | 1 | 1 | CRITICAL | CRITICAL |
| 101 | 2 | 1 | CRITICAL | CRITICAL |
| 101 | 3 | 1 | CRITICAL | CRITICAL |
| 101 | 4 | 1 | HIGH | CRITICAL |
| 100 | 5 | 5 | HIGH | HIGH |
| 17 | 6 | 6 | HIGH | HIGH |
| 16 | 7 | 7 | MEDIUM | MEDIUM |
| 10 | 8 | 8 | MEDIUM | MEDIUM |
| 5 | 9 | 9 | MEDIUM | MEDIUM |
| 4 | 10 | 10 | LOW | LOW |
| 2 | 11 | 11 | LOW | LOW |
| 1 | 12 | 12 | LOW | LOW |
✅ 이와 같이 ROW_NUMBER에 의한 분류의 경우, 같은 사이즈임에도 불구하고 다른 이름으로 분류되는 경우가 생긴다!
풀이(1)
대장균 개체의 크기를 특정 백분위로 구분하여 각각 COLONY_NAME으로 분류해야 하기 때문에 ROW_NUMBER()를 사용한다.
SELECT id
, CASE
WHEN row_n <= (SELECT COUNT(*) FROM ECOLI_DATA) * 1/4 THEN 'CRITICAL'
WHEN row_n <= (SELECT COUNT(*) FROM ECOLI_DATA) * 2/4 THEN 'HIGH'
WHEN row_n <= (SELECT COUNT(*) FROM ECOLI_DATA) * 3/4 THEN 'MEDIUM'
ELSE 'LOW'
END AS colony_name
FROM (
SELECT *
, ROW_NUMBER() OVER (ORDER BY size_of_colony DESC) AS row_n
-- , RANK() OVER (ORDER BY size_of_colony DESC) AS rK
FROM ECOLI_DATA
) AS step1
ORDER BY id
✅ FROM절 서브쿼리 :
대장균 개체 크기 기준 내림차순 정렬한 뒤, 크기가 같아도 중복되지 않게끔 순위를 부여한 테이블
✅ 메인쿼리 :
총 데이터의 수가 4의 배수라는 조건이 있기 때문에, CASE 구문을 활용하여 상위 0~25%, 26~50%, 51~75%, 76~100%에 해당되는지 조건을 형성한다.
📌혹시나
상위 0~25%에 해당하는 row는 첫번째 WHEN 조건에서 걸러지기 때문에, 그 이후에 등장하는 WHEN 조건에 포함되지 않는 CASE 구문 동작 원리를 알아두자.
풀이(2)
윈도우 함수 PERCENT_RANK()를 사용하여 접근해 보자. 이 함수는 데이터 집합 내에서 특정 행의 상대적 순위를 백분율로 계산하여 반환하는 윈도우 함수이다. 0~1 값을 반환하며, 특정 값이 전체 데이터에서 차지하는 위치를 확인할 때 유용하다.
SELECT id
, CASE
WHEN pct_rk <= 0.25 THEN 'CRITICAL'
WHEN pct_rk <= 0.5 THEN 'HIGH'
WHEN pct_rk <= 0.75 THEN 'MEDIUM'
ELSE 'LOW'
END AS colony_name
FROM (
SELECT *
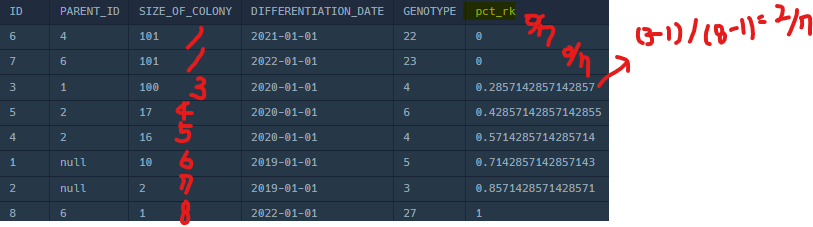
, PERCENT_RANK() OVER (ORDER BY size_of_colony DESC) AS pct_rk
FROM ECOLI_DATA
) AS step1
ORDER BY id
✅ FROM절 서브쿼리 :
대장균 개체 크기 기준 내림차순 정렬한 뒤, 각 행의 상대적 순위를 백분율로 계산한 테이블

✅ 메인쿼리 :
총 데이터의 수가 4의 배수라는 조건이 있기 때문에, CASE 구문을 활용하여 상위 0~25%, 26~50%, 51~75%, 76~100%에 해당되는지 조건을 형성한다.
📌PERCENT_RANK() 함수 특징
1. 0 ~ 1 사이의 값을 반환한다. (0이 가장 낮은 순위, 1이 가장 높은 순위를 의미)
2. 계산 공식 :
PERCENT_RANK = (RANK - 1) / (Total Rows - 1)
3. 첫 번째 행은 항상 0을 반환
4. 중복 값인 경우 동일한 값을 반환
💡쉽게 이해하기
RANK() 함수 동작 원리에 따라 1, 1, 3, 4, ...와 같이 순위를 부여한 후에, 위 계산 공식과 같이 계산되는 동작 원리‼️
'SQL > 프로그래머스' 카테고리의 다른 글
| 자동차 대여 기록 별 대여 금액 구하기 | Lv.4 (1) | 2025.04.21 |
|---|---|
| 특정 기간동안 대여 가능한 자동차들의 대여비용 구하기 | Lv.4💡 (0) | 2025.04.14 |
| 오랜 기간 보호한 동물(2) | Lv.3 (0) | 2025.04.08 |
| 자동차 대여 기록에서 '대여중 / 대여 가능' 구분하기 | Lv.3💡 (0) | 2025.04.07 |
| 대장균들의 자식의 수 구하기 | Lv.3 (0) | 2025.04.05 |
