
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- rank
- 데이터분석
- 독서
- 서브쿼리
- pandas
- 퍼널분석
- 프로그래머스
- 윈도우 함수
- 데이터리안
- 린분석
- leetcode
- 순위함수
- 누적합
- LEFTJOIN
- 취준
- advent of sql
- dense_rank
- python
- Datarian
- Retention
- 그로스해킹
- regexp
- SolveSQL
- SQL
- row_number
- 리텐션
- 신입 데이터분석가
- MYSQL
- 윈도우함수
- funnel
Archives
- Today
- Total
데이터 분석
[Pandas] DataFrame.pivot() / pivot_table() 본문
DataFrame.pivot()
DataFrame.pivot() 메서드는 Pandas에서 데이터를 재구조화하는 데 사용한다.
이를 통해 열(column)을 재배치하거나 데이터의 행(row)과 열을 기준에 따라 재구성할 수 있다.
- 직접적인 데이터 변환:
- 고유한 값만을 허용하며, 중복 값이 있을 경우 오류 발생
- 세 가지 주요 매개변수:
- index: 새로운 DataFrame에서 행으로 사용할 열
- columns: 새로운 DataFrame에서 열로 사용할 열
- values: 새로운 DataFrame에서 값으로 사용할 열
# 1
아래 국가별 5세 이하 사망 비율 통계 자료가 있다.

위 데이터를 나라에 따른 년도별 사망률을 알아볼 수 있게 데이터를 재구조화 해보자.
df2.pivot(index='Location', columns='Period', values='First Tooltip').head()
# 2
아래와 같은 데이터프레임을 가정해보자.
data = {
'Date': ['2023-12-01', '2023-12-01', '2023-12-02', '2023-12-02'],
'City': ['Seoul', 'Busan', 'Seoul', 'Busan'],
'Temperature': [5, 10, 6, 11]
}
df = pd.DataFrame(data)
df
이를 갖고 pivot을 활용해보자.
df.pivot(index='Date', columns='City', values='Temperature')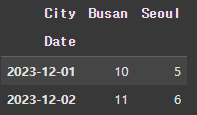
DataFrame.pivot_table()
DataFrame.pivot_table() 메서드는 pivot()과 유사하지만, 중복된 데이터 처리 및 집계 기능이 추가된다.
이를 통해 동일한 (index, column) 조합에 대해 특정 집계 함수를 적용할 수 있다.
- 중복 값이 있을 경우, 오류 대신 집계 함수를 사용하여 처리
- 기본 집계 함수는 평균(mean)이며, aggfunc 매개변수로 변경 가능
- 불완전한 데이터(NaN)를 처리하기 위한 fill_value 옵션 제공
# 1
아래 올림픽 메달리스트 정보 데이터가 있다.

위 데이터 중 한국 데이터만 추출하여 년도에 따른 메달 종류별 개수를 집계해보자.
df2 = df[df['Country'] == 'KOR']
df2.pivot_table(index='Year', columns='Medal', aggfunc='size', fill_value=0)
# 2
다음은 전체 데이터에서 sport 종류에 따른 성별 인원을 구해보자.
df.pivot_table(index='Sport', columns='Gender', aggfunc='size')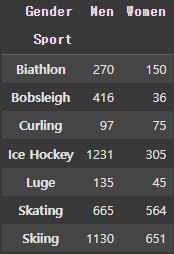
마무리
| 특징 | pivot | pivot_table |
| 중복 데이터 처리 | 오류 발생 | 지정된 aggfunc를 사용해 처리 |
| 기본 동작 | 단순 재구조화 | 재구조화 + 집계 |
| 집계 함수 | 미지원 | mean, sum, min, size 등 지원 |
| NaN 처리 | 미지원 | fill_value 옵션 지원 |
- pivot()은 단순 데이터 재구조화에 사용되며, 중복 데이터가 없어야 한다.
- pivot_table()은 중복 데이터 처리와 집계가 필요한 경우에 적합하다.
데이터 집계가 필요하거나 데이터가 중복될 가능성이 있다면 pivot_table()을 사용하는 것이 더 유연하다.
'Python > Pandas' 카테고리의 다른 글
| [Pandas] 주소 데이터 정제하기 | str.split() (0) | 2025.02.13 |
|---|---|
| [Pandas] 날짜 데이터 다루기 | 서울시 미세먼지 데이터 (2) | 2024.12.18 |
| [Pandas] 날짜 데이터 다루기 (2) | 2024.12.17 |
| [Pandas] datetime 컬럼 가공 | 잘못된 연도 값 조정하기 (2) | 2024.12.14 |
| [Pandas] Series.map() & DataFrame.apply() 활용 (0) | 2024.12.13 |
'Python/Pandas' Related Articles
more


